

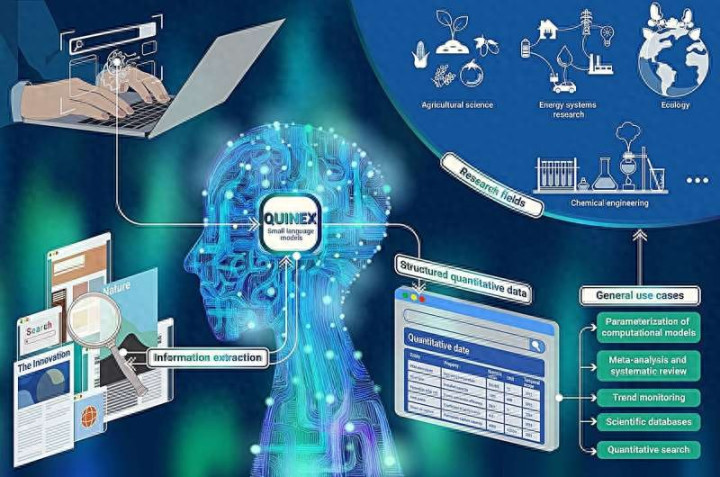
科学数据正在以惊东说念主的速率堆积,但大量有价值的数字依然被埋在论文文本里,恭候东说念主工去发现。
德国于利希商榷中心的商榷团队拓荒了一套名为Quinex的AI框架,迥殊用于自动识别科学论文中的定量数据,将洒落在笔墨陈诉中的数字、单元、测量条件等信息,整理成结构化的可用数据集。有关效果已发表在《翻新》杂志上。
这件事听起来像是笔墨处理器具的升级版,但它科罚的问题远比看起来更进攻。
数据就在那里,但没东说念主能一齐读完
在动力、吹法螺、材料科学等商榷边界,每一篇论文里都密布着数字:效用百分比、温度边界、分娩资本、碳排放量。这些数据关于建筑模子、识别趋势、制定策略具有顺利价值。
问题是,这些数字并不存在于整王人的表格里,它们藏在句子的中间,夹在才略描述和布景讲明之间,需要东说念主读懂陡立文才能判断它的含义。
更难办的是,有关论文的数目正在以指数级增长。以动力转型边界为例,每年新发表的商榷论文照旧远超任何团队手工处理的上限。念念要系统性地汇总某项时候在以前十年的效用演变,靠东说念主工阅读索求险些是弗成能完成的任务。
Quinex念念要科罚的,恰是这个卡口。
Quinex是“定量信息索求”的缩写,其中枢是历程迥殊锻真金不怕火的话语模子,八成识别科学文本中的数值,开云体育中国官方网站将数值与对应单元匹配,并判断这个数字描述的是什么、在什么条件下测得、来自那儿、时分节点是何时。
举一个具体例子:论文中出现“2025年假定效用水平为63%至71%”这么的句子,Quinex会将其领路为包含年份、效用边界、测量才略和文件开端的结构化数据条款,而不是只是索求“63%”和“71%”两个孑然的数字。
这种对陡立文的谐和才能,是Quinex区别于浅显数字索求器具的关节地方。
在准确率方面,Quinex在数字及有关单元识别上的F1准确率约为98%,在定量属性分类和实体分类上离别达到87%和82%。这些数据来自迥殊构建的锻真金不怕火数据集和才略论矫正,在同类系统中处于逾越水平。
轻量、灵通,让更多商榷者用得上
值得心理的是,Quinex并非依赖宏大的私有大模子,UEDBETapp官网版而是基于相对袖珍、高效的灵通话语模子构建。
这个采用有其明确的逻辑。大型闭塞模子经营资本昂贵,部署门槛高,关于资源有限的商榷机构并不友好。于利希团队的指标是拓荒一个“强盛、透明且资源高效”的器具,让AI缓助的科学数据分析委果具备可及性。
在本色测试中,商榷团队将Quinex专揽于来自多个边界的数千篇科学摘录,系统顺利索求了种种动力时候的电力分娩资本、东说念主体最大摄氧量、地震震级与位置数据,以及光伏材料的能隙数值,索求适度与参考数据高度吻合。
讲求该花式的Jann Weinand博士暗示,Quinex使AI在科学数据分析中更易赢得,而这恰是团队从一初始就设定的指标。
于利希商榷中心已将Quinex当作开源花式对外发布,公共商榷东说念主员不错免费测试、膨胀和调节这套系统,使其合乎各自边界的需求,从动力商榷到化学、生物医学均可障翳。
虽然,Quinex并非见缝就钻。团队坦承,当关节援用信息散布在文本各处时,系统偶然会出现诬陷。领衔作家Jan Göpfert明确暗示,数字和单元的识别额外可靠,因为它们顺利来自原文,不存在“幻觉”问题,但对陡立文的判断仍有出错的可能。
正因如斯,团队将Quinex定位为缓助器具而非替代品,每一个被识别的数字都不错回首到原始开端,必要时在原文中顺利标注,解读适度的包袱仍由商榷者承担。
接下来,团队贪图通过引入更多边界专属的锻真金不怕火数据集和模子,进一步升迁系统在细分边界的合乎性和精度。
科研的急流在加快UEDBETapp下载,能匡助商榷者在数据海洋里更快找到宗旨的器具,正在变得越来越弗成或缺。
澳门在线赌钱娱乐网入口 备案号:
备案号: